ChatGLM本地模型部署
ChatGLM2-6B
ChatGLM2-6B 简介
ChatGLM2-6B 是开源中英双语对话模型 ChatGLM-6B 的第二代版本,具体介绍可参阅 ChatGLM2-6B 项目主页
注意
ChatGLM2-6B 权重对学术研究完全开放,在获得官方的书面许可后,亦允许商业使用。本教程只是介绍了一种用法,无权给予任何授权!
推荐配置
依据官方数据,同样是生成 8192 长度,量化等级为 FP16 要占用 12.8GB 显存、int8 为 8.1GB 显存、int4 为 5.1GB 显存,量化后会稍微影响性能,但不多。
| 类型 | 内存 | 显存 | 硬盘空间 |
|---|---|---|---|
| fp16 | >=16GB | >=16GB | >=25GB |
| int8 | >=16GB | >=9GB | >=25GB |
| int4 | >=16GB | >=6GB | >=25GB |
源码部署
提示
根据上面的环境配置配置好环境,具体教程自行百度;
可参考的部署文章: https://blog.csdn.net/lovelylord/article/details/132349967
- 1、从GitHub仓库中拉取代码
# 1.从GitHub仓库中拉取代码
git clone https://github.com/THUDM/ChatGLM2-6B
# 2.进入下载源码的目录
cd ChatGLM2-6B2、下载python文件: 点击Python文件
- 得到两个文件: openai_ai.py 和 requirements.txt
- 把这两个文件替换到 ChatGLM2-6B 目录里面
3、在命令行输入命令(安装依赖):
pip install -r requirments.txt- 建议使用python的虚拟环境,以免产生一些不必要的麻烦。
4、运行项目:
python openai_api.py --model 16这里的数字根据上面的配置进行选择。- 然后等待模型下载,直到模型加载完毕为止。如果出现报错先问百度。
- 这里可能需要科学上网
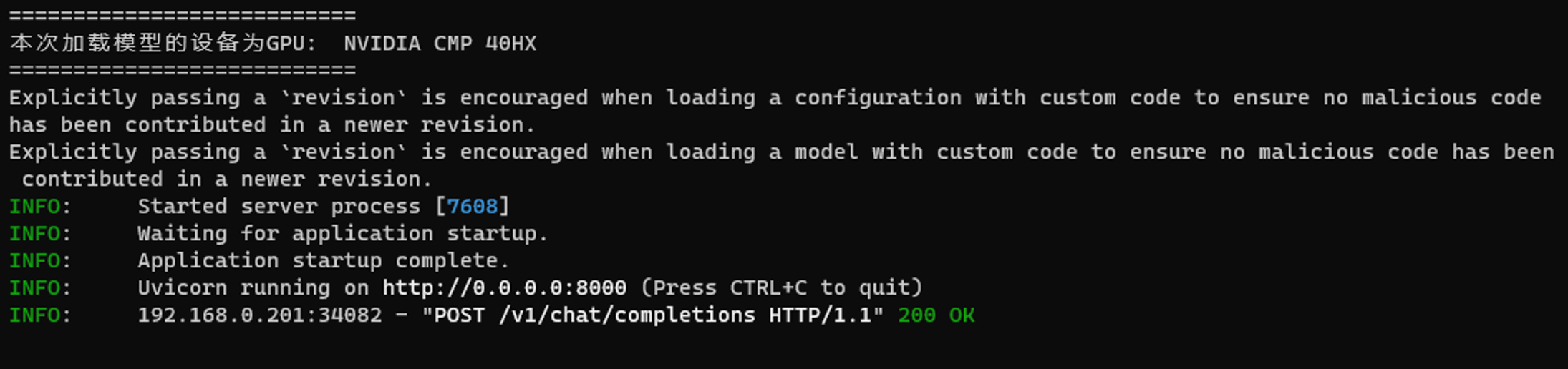
5、启动成功后应该会显示如下地址:
提示
这里的 http://0.0.0.0:8000 就是连接地址。
关于 openai_api.py 启动的一些参数
| 参数名 | 可选值 | 默认值 |
|---|---|---|
| --device | cuda=显卡运行, cpu=cpu运行 | cuda |
| --path | local=本地下载的模型运行, thudm=线上自动下载 | thudm |
| --model | 4=chatglm2-6b-int4, 8=chatglm2-6b-int8, 16=chatglm2-6b | 16 |
- 说明:
- 如果你
--path参数设置为 local, 那需要你先把模型下载下来, 放到 ChatGLM2-6B/models 目录下 - 比如: ChatGLM2-6B/models/chatglm2-6b-int4
- 然后再去运行:
python openai_api.py --model 4 --path local
- 如果你
接口测试
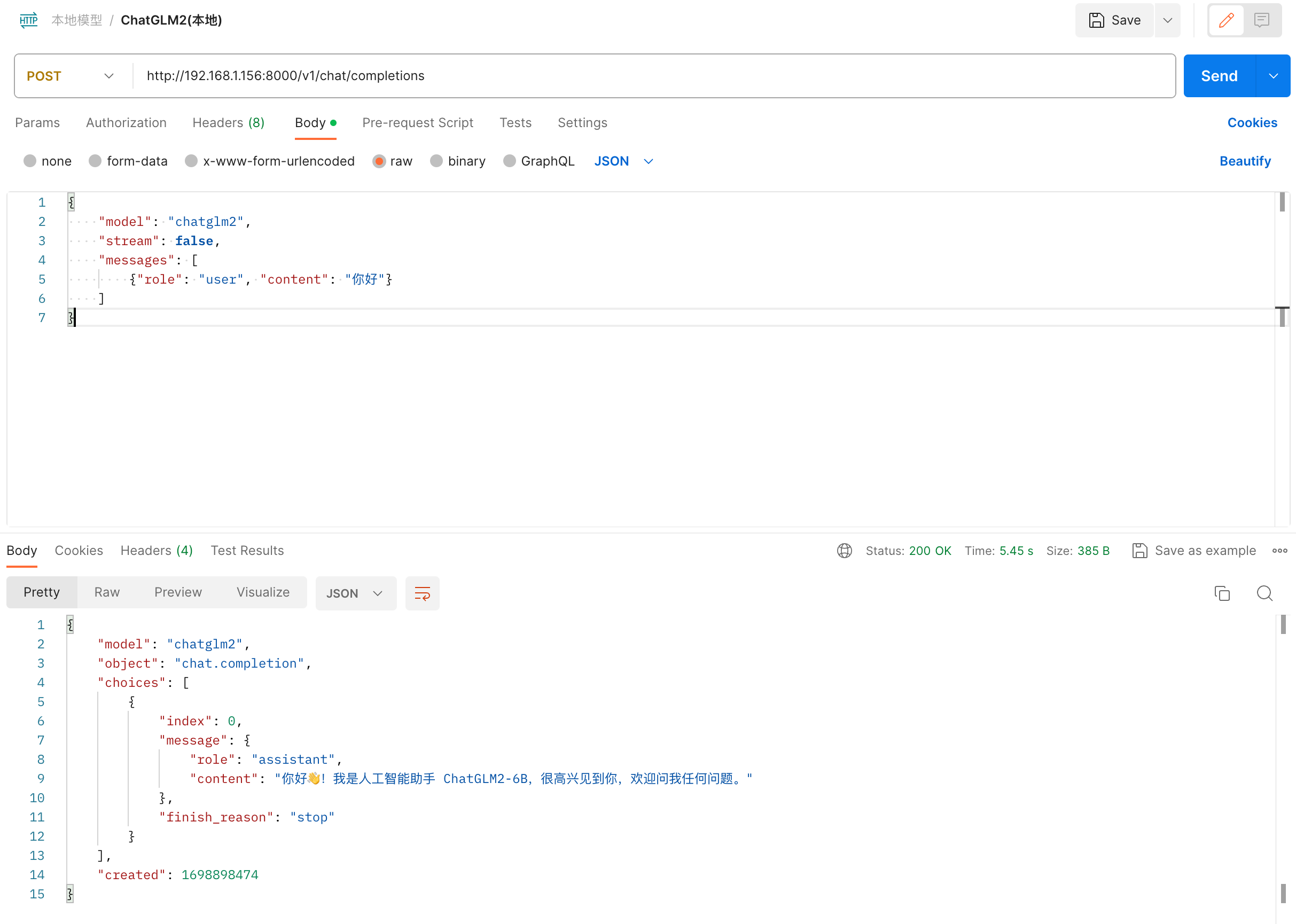
接入到系统
ChatGLM3-6B
注意
部署方案和ChatGLM2-6B的方式基本上是一样的。
- 1、从GitHub仓库中拉取代码
# 1.从GitHub仓库中拉取代码
https://github.com/THUDM/ChatGLM3
# 2.进入下载源码的目录
cd ChatGLM3-6B- 2、在命令行输入命令(安装依赖)
shell
# PS: 建议使用python的虚拟环境,以免产生一些不必要的麻烦。
pip install -r requirments.txt- 3、安装cuda依赖 (如果你是用显卡运行,否则忽略该步骤)
shell
3.1、我这边是使用windows系统,首先需要运行一下命令看一下CUDA的版本
在cmd终端运行: nvidia-smi
我这边得到的版本是: CUDA Version: 12.2
3.2、然后去torch官网中查看CUDA适配的torch版本
官网: https://pytorch.org/get-started/locally/
3.3、进入网站后按版本选择安装命令 (根据你电脑实际情况选择)
PyTorch Build : Stable(2.1.0)
Your OS : Windows
Package : Pip
Language : Python
Compute Platform : CUDA 12.1
Run this Command : pip3 install torch trchvision ......
3.4、你只需要复制后面 Run this Command 选项的这串 pip3的安装命令, 然后回到你电脑的终端运行即可4、下载python文件: 点击Python文件
- 得到1个文件: openai_ai.py (此文件就是启动文件)
- 把这个文件放到到 ChatGLM3-6B 目录里面
5、下载模型文件到本地:
- 下载地址: https://modelscope.cn/models/ZhipuAI/chatglm3-6b/files
- 把里面列表所有文件都下载回来, 并统一用一个名为 chatglm3-6b 的文件夹存放
- 然后把该文件夹的(含所有内容) 一并移动到 ChatGLM3-6B/models 目录下面
6、运行项目:
python openai_api.py这里的数字根据上面的配置进行选择。- 然后等待模型下载,直到模型加载完毕为止。如果出现报错先问百度。
- 这里可能需要科学上网 (默认是需要从 www.huggingface.org 上面下载模型文件回来的, 时间会比较长)
- 以上什么参数都没有的实际运行命令是
python openai_api.py --device cuda --path local --model 4- 该命令的意思是 启动脚本 使用 【显卡驱动、使用本地下载的模型文件(即上面第5步) 、 使用量化版本】
- 为什么默认使用量化版本? 因为如果你的显卡显存不够13GB是没办法运行正常的版本的。
- 如果运行正常版本? 把参数 --model 4 改成 --model 16 即可。
- 问: 我要运行32k的模型呢? 答: 那你就去下载32k的模型 当然放到源码的models目录下面, 修改一些运行命令运行就行了
7、运行后的效果
shell
(venv) PS E:\AI\GLM3> python .\openai_api.py
===========================
本次加载模型的设备为GPU: NVIDIA CMP 40HX
===========================
正在启动的是量化版本...
Loading checkpoint shards: 100%|█████████████████████████████████████████████████████████| 7/7 [00:23<00:00, 3.41s/it]
INFO: Started server process [11136]
INFO: Waiting for application startup.
INFO: Application startup complete.
INFO: Uvicorn running on http://0.0.0.0:8100 (Press CTRL+C to quit)
## 注意
## 注意
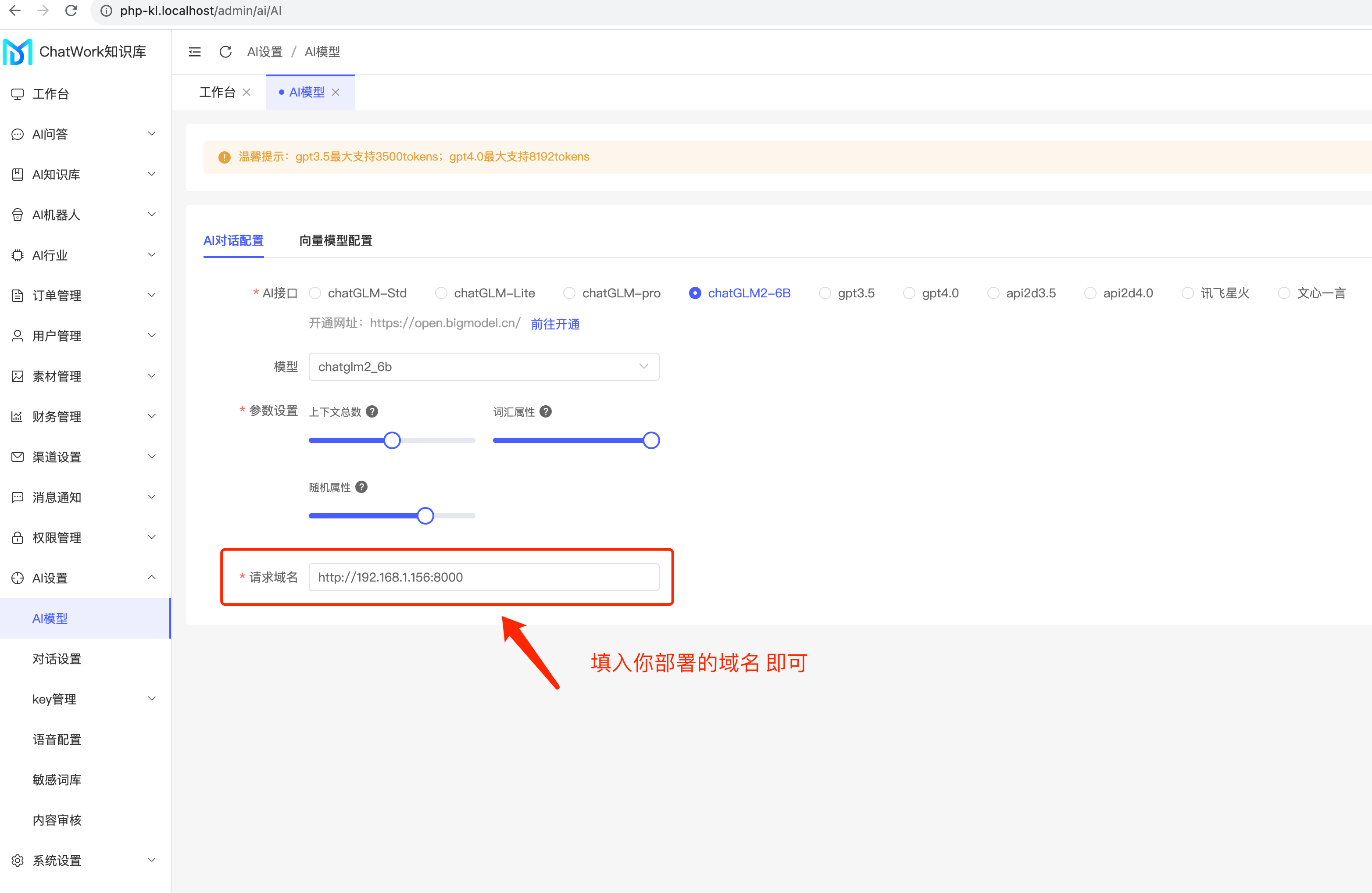
## 这个就是你的运行接口,配置到知识库系统里那个
接口: http://0.0.0.0:8100- 8、关于 openai_api.py 启动的一些参数
| 参数名 | 可选值 | 默认值 |
|---|---|---|
| --device | cuda=显卡运行, cpu=cpu运行 | cuda |
| --path | local=本地下载的模型运行, thudm=线上自动下载 | thudm |
| --model | 4=量化模型, 16=chatglm3-6b, 32=chatglm2-6b-32k, 128=chatglm2-6b-32k | 4 |
- 说明:
- 如果你
--path参数设置为 local, 那需要你先把模型下载下来, 放到 ChatGLM2-6B/models 目录下 - 比如: ChatGLM3-6B/models/chatglm3-6b
- 然后再去运行:
python openai_api.py --model 4 --path local - PS: 温馨小提示,GLM3不再像之前GLM2那样单独提供量化版本模型下载, 现在是量化模型直接继承在 chatglm3-6b模型上,使用运行命令作为区分。
- 如果你